
Table Comparison app: quality control and changes
Today I’d like to share with you a helpful tool, which allows comparing two tables based on their QVD-files that supposedly have the same data. This tool highlights such inconsistencies between two data sets as missing fields, records and even differences between the values in each field for each particular record.
You might ask why do you need this kind of tool?
I came up with this idea during one of the projects when we quickly created an application and applied a number of data transformations on the Qlik level to satisfy business needs. One of the tables was the Equipment DIM table were 26 different tables from the Data Warehouse (DWH) combined with additional business rules. As we all know, Qlik can do everything, or close to it. However, it’s not always the best tool for a job. In this case, the business requirement was to enable the re-use of applied business logic by other applications and even by different BI tools in the future. That’s why I suggested migrating that logic into the DWH and build an artefact (table, view etc.).
The next question is: how you know that the logic in DWH was applied correctly, and here, the Table Comparison app takes its turn.
You might ask why do you need this kind of tool?
I came up with this idea during one of the projects when we quickly created an application and applied a number of data transformations on the Qlik level to satisfy business needs. One of the tables was the Equipment DIM table were 26 different tables from the Data Warehouse (DWH) combined with additional business rules. As we all know, Qlik can do everything, or close to it. However, it’s not always the best tool for a job. In this case, the business requirement was to enable the re-use of applied business logic by other applications and even by different BI tools in the future. That’s why I suggested migrating that logic into the DWH and build an artefact (table, view etc.).
The next question is: how you know that the logic in DWH was applied correctly, and here, the Table Comparison app takes its turn.
ILLUSTRATION: TOMASZ WALENTA Let me show you how it works!
First of all, make sure that you have stored the data from the tables into QVD-files.
The assumption is that both of your QVD-files have the same field names for the columns with the same data.
SetUp sheet allows you to configure the following settings:
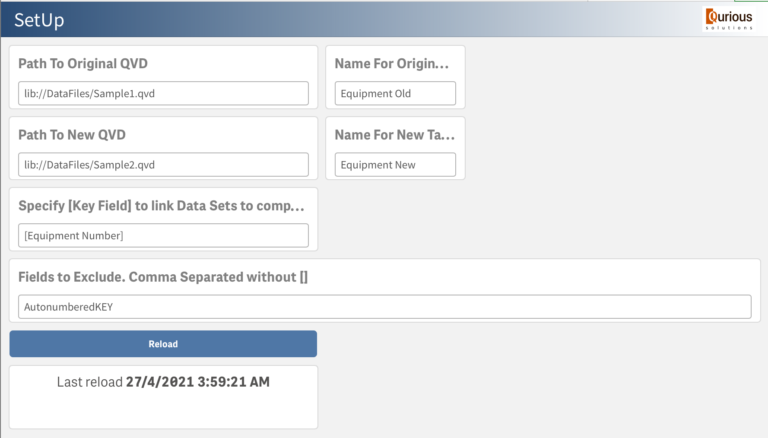
- Path to a QVD file with original data and table name
- Path to a QVD file with a new version of the data and table name
- The name of the field two tables should be connected and compared on. This is your unique identifier for each record.
- The fields you might want to exclude from the comparison. A good example is a field with autonumbered KEY in QVD.
When you finish with the configuration, click Reload button.
I used the following sample data sets to demonstrate how it works. You can find them on the first sheet in the Load Script.
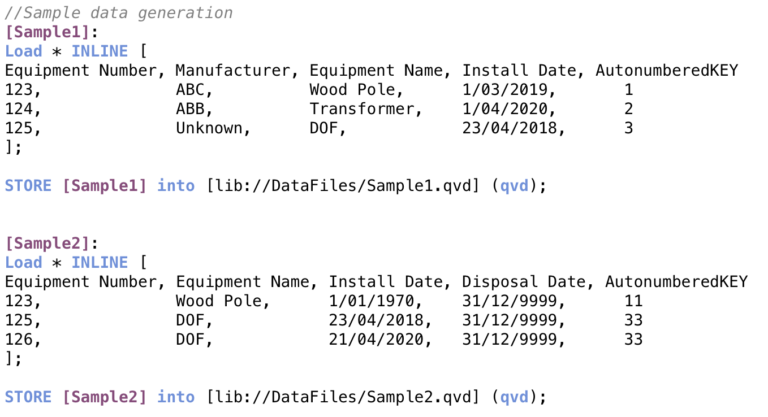
The reload time depends on the data volume. However, it did show good performance on the data sets with millions of rows.
When data reload finishes, you can jump onto the next sheet ‘Field Names Comparison’ to see the results:
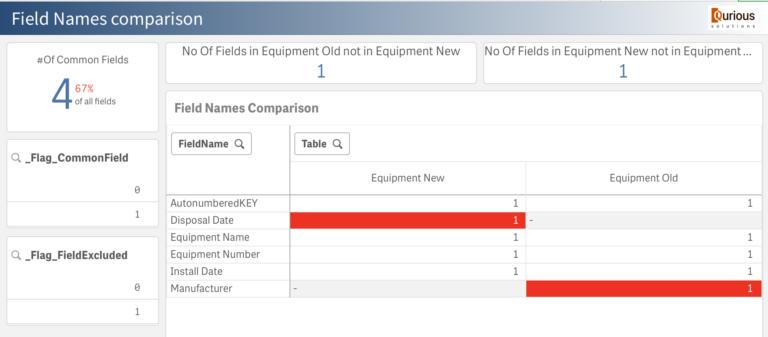
In this example, you can see straight away that the field names in our two tables do not match. This screen helps you to identify them.
Field Names comparison is pretty simple. However, quite often, the devil is in details. That’s why I created another sheet that helps you to see if there are any missing records or if values in two datasets are different for the same record. You can find this information on the ‘Values Comparison’ sheet.
First of all, it shows you a list of inconsistencies found:
Field Names comparison is pretty simple. However, quite often, the devil is in details. That’s why I created another sheet that helps you to see if there are any missing records or if values in two datasets are different for the same record. You can find this information on the ‘Values Comparison’ sheet.
First of all, it shows you a list of inconsistencies found:
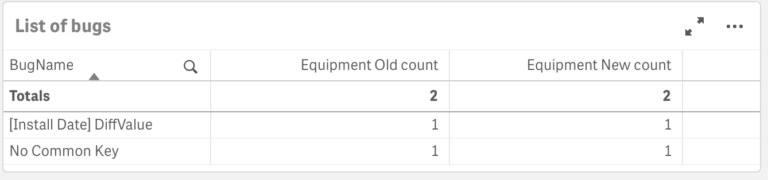
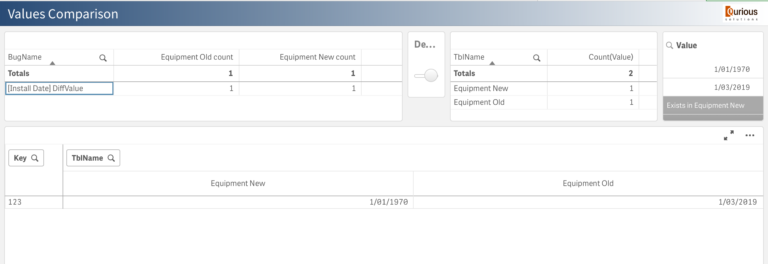
You can pick one and switch on the Details slider to see the differences:
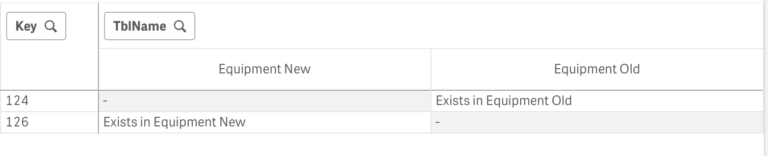
When I pick ‘No Common Key’ bug, it shows the missing records in the following way:
Please note, this analysis won’t show any information about what’s correct. It shows only the inconsistencies between the two datasets found. You can assume that all other not displayed things are in order.
So, this tool just helped us to see that there are several problems in this data set:
There are two not matching fields (one in Old Dataset and one in New Dataset) The record with the key 123 has different values in the field [Install Date]. Record 124 doesn’t exist in a new dataset, and record 126 is missing in Old one. There might be many reasons why the datasets do not match exactly. However, it’s an excellent start to have a chat with your colleagues to find these reasons and resolve the issues.
You are welcome to download this app from here if you ever need to compare two versions of the same data. Enjoy!
Leave a comment if you have any questions, have an idea for improvement or want to leave your feedback.
So, this tool just helped us to see that there are several problems in this data set:
There are two not matching fields (one in Old Dataset and one in New Dataset) The record with the key 123 has different values in the field [Install Date]. Record 124 doesn’t exist in a new dataset, and record 126 is missing in Old one. There might be many reasons why the datasets do not match exactly. However, it’s an excellent start to have a chat with your colleagues to find these reasons and resolve the issues.
You are welcome to download this app from here if you ever need to compare two versions of the same data. Enjoy!
Leave a comment if you have any questions, have an idea for improvement or want to leave your feedback.
